В прошлой статье я обзорно прошелся по различным типам мониторинга простых веб-проектов и веб-сайтов, когда от сайта не требуется уровня надежности 99,99%, когда время реакции может составлять часы или дни. В общем, когда все просто. В этой статье я раскрою механизмы мониторинга облачной инфраструктуры, когда простого сигнала доступен/не доступен совсем не достаточно, чтобы понять, в чем проблемы, и как их оперативно решить. Или же когда решение проблемы может требовать большого количества действий, автоматизировать которые можно только частично.
Обычно уровень надежности инфраструктуры проекта позволяет оставить время реакции на возникшие проблемы таким же — часы или даже дни. Но при этом есть ряд мест, решения по которым должны приниматься в (полу)автоматическом режиме, чтобы исключить человеческий фактор и свести время простоя системы к минимуму. О триггерах таких решений речь пойдет ниже. Хочу сразу отметить, что почти все описанные технологии мониторинга используются в новом облачном сервисе социального интранета - Битрикс24.
При построении отказоустойчивой распределенной инфраструктуры кроме обеспечения нескольких уровней надежности обычно закладывают и несколько уровней мониторинга системы. Среди них можно выделить:
Munin выдает большое количество информации о состоянии требуемого сервера. К наиболее часто проверяемым моментам относят:
Немного картинок мониторинга реальной системы (загрузка и база данных)
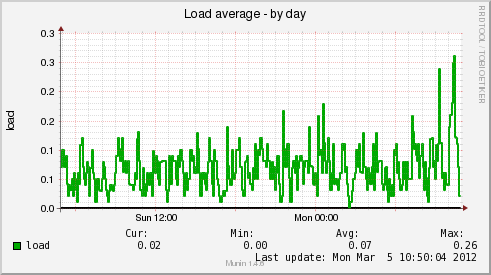
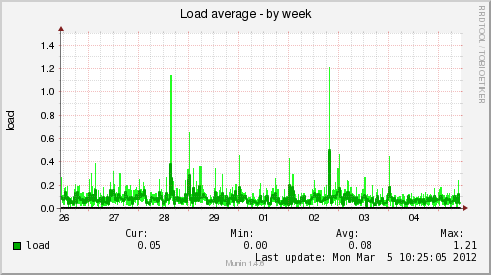
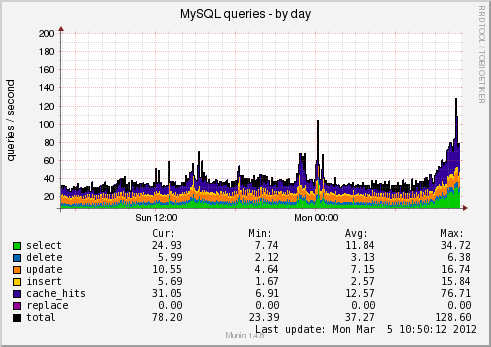

Для примера, скрипт проверки свободного места в InnoDB таблице MySQL
## Tunable parameters with defaults
MYSQL="${mysql:-/usr/bin/mysql}"
MYSQLOPTS="${mysqlopts:---user=munin --password=munin --host=localhost}"
WARNING=${warning:-2147483648} # 2GB
CRITICAL=${critical:-1073741824} # 1GB
## No user serviceable parts below
if [ "$1" = "config" ]; then
echo 'graph_title MySQL InnoDB free tablespace'
echo 'graph_args --base 1024'
echo 'graph_vlabel Bytes'
echo 'graph_category mysql'
echo 'graph_info Amount of free bytes in the InnoDB tablespace'
echo 'free.label Bytes free'
echo 'free.type GAUGE'
echo 'free.min 0'
echo 'free.warning' $WARNING:
echo 'free.critical' $CRITICAL:
exit 0
fi
# Get freespace from mysql
freespace=$($MYSQL $MYSQLOPTS --batch --skip-column-names --execute \
"SELECT table_comment FROM tables WHERE TABLE_SCHEMA = 'munin_innodb'" \
information_schema);
retval=$?
# Sanity checks
if (( retval > 0 )); then
echo "Error: mysql command returned status $retval" 1>&2
exit -1
fi
if [ -z "$freespace" ]; then
echo "Error: mysql command returned no output" 1>&2
exit -1
fi
# Return freespace
echo $freespace | awk '/InnoDB free:/ {print "free.value", $3 * 1024}'Большой список популярных плагинов можно найти в GIT-репозитории
Nagios как решение для мониторинга безусловно хорош. Но нужно быть готовым к тому, что кроме него придется использовать еще собственные скрипты и(ли) Pinba (или аналогичное решения дл вашего языка программирования). Pinba оперирует UDP-пакетами и собирает информацию о времени выполнения скриптов, объеме памяти и кодах ошибок. В принципе, этого достаточно для создания полной картины происходящего и обеспечения требуемого уровня надежности сервиса в автоматическом режиме.
На уровне внутреннего мониторинга уже можно принимать решения о выделении дополнительных мощностей (если это возможно автоматически — то достаточно просто отслеживать средний уровень загрузки процессора на серверах приложений или базы данных, если это производится в ручном режиме — то можно высылать письма или jabber-сообщения) или их отключении. Также в случае возникновения аномального количества ошибок (обычно это происходит при отказе оборудования либо ошибки в новой версии веб-сервиса, и что является причиной, всегда можно установить за счет дополнительных проверок) можно слать уже экстренные уведомления по смс или звонить по телефону.
Также очень удобно настроить автоматическое добавление (или удаление) тестов при увеличении точек проверки (например, серверов ли пользовательских сайтов) с заданными шаблонами: например, проверка главной страницы, распределение времени выполнения PHP, распределение использования памяти для PHP, число nginx и PHP ошибок.
Мониторинг на уровне облачной инфраструктуры предлагает не такое большое количество провайдеров, и он является, скорее, информационным: реальные решения принимаются либо на основе внутренних данных, либо внешнего состояния системы. На промежуточном уровне можно только собирать статистику или подтверждать внутреннее состояние инфраструктуры.
Для Amazon (CloudWatch) здесь доступны следующие возможности проверки:
Уже по результатам мониторинга промежуточного (на уровне балансировщиков) можно принимать обоснованное решение о выделении или закрытии машин (инстансов) в кластере. Именно так и делается в Битрикс24: как только состояние загруженности серверов приложений становится слишком большой (больше 60%), то начинают запускаться новые инстансы. И наоборот, при снижени нагрузк меньше 40% инстансы закрываются.
Здесь выбор решений очень большой. Если требуется отслеживать состояние серверов по всему миру, то лучшее решение — это Pingdom. Для российских реалий подойдет PingAdmin или WEBO Pulsar (у них есть сеть серверов по России). Особенно удобно настроить проверку из нескольких точек (например, Москва+Санкт-Петербург) и дергать удаленный скрипт уведомления, если сервис не доступен в течение 1-2 минут. Если при этом есть какие-либо проблемы внутри, то можно сразу переключаться на план «Б» (выключать неработающие сервера, сыпать уведомлениями и т.д.).
К дополнительным плюсам внешнего мониторинга можно отнести проверку реального времени ответа на стороне сервера (или реальных сетевых задержек). По этому параметру также можно настроить уведомления. Как дополнительная возможность в случае использования CDN: можно отслеживать полное время загрузки страниц сервиса и отключать или включать CDN для разных регионов.
P.S. статья обзорная, больше про архитектуру мониторинга крупных проектов. О конкретных прикладных вещах расскажу в следующих статьях.
![]() © 2016 ООО ВЕБО
© 2016 ООО ВЕБО